Chapter 1. Parallel computing
Fundamental types of parallelism in
application
l Task parallelism : Distributing the task or functions
l Data parallelism : Distributing the data across multiple cores
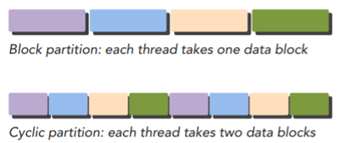
n Block partitioning : Each thread takes one portion of the data
n Cyclic partitioning : Each thread takes more than one portion of the
data
n Note. Distributing the data, I have to know How the data is stored
physically and how the execution of each thread is ordered.(Computer
architecture)
n Note. The performance of a program is usually sensitive to the block
size
Computer Architecture
l Flynn’s Taxonomy that used classification scheme widely
n SISD : A serial architecture, One core
n SIMD : Multiple cores, Vector computer, Execute the same instruction
stream, different data streams, most modern computers employ this. Writing code
on the CPU, programmers can continue to think sequentially achieve parallel
speed-up. Because the compiler takes care of the details
n MISD : uncommon architecture.
n MIMD : each executing independent instructions. Many MIMD
architectures also include SIMD execution sub-components.
l Advantage 3 objectives
n Latency is the time it takes for an operation to start and complete
n Bandwidth is the amount of data that can be processed per unit of
time
n Throughput is the amount of operations that can be processed per
unit of time
l GPU vs CPU
n CPU core, relatively heavy-weight, is designed for very complex
control logic, seeking to optimize the execution of sequential programs.
n GPU core, relatively light-eight, is optimized for data-parallel
tasks with simpler control logic, focusing on the throughput of parallel
programs.
l Heterogeneous computing
n Using Different more than two device ex. CPU and GPU
n GPU